1.问题提出
为了实现自走的路径,并尽量避免障碍,设计一个路径。如图所示,当机器人在图中的任意网格中时,怎样让它明白周围环境,最终到达目标位置。
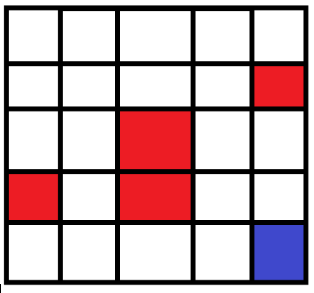
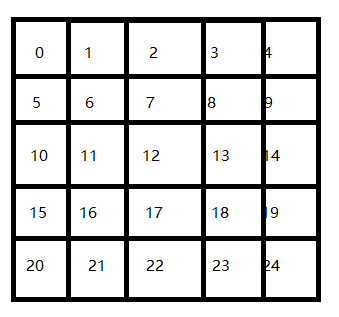
这里给出一个运行结果,首先给他们编号如下:作为位置的标识。
然后利用Q-Learning的奖赏机制,完成数据表单更新,最终更新如下:
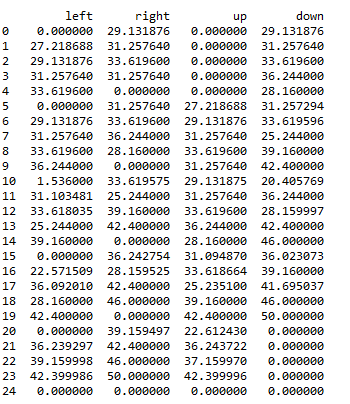
在机器人实际选择路径时,按照该表中的最大值选择,最终走到24号位置,并避开了红色方块。
如初始位置在4时候,首先选择了最大值向左到3,然后在3处选择了最大值向下,然后到8处选择了向下,等等,最终完成路径的选择。而这种选择正是使用Q-Learning实现的。
2.Q-learning的想法
2.1奖赏机制
在一个陌生的环境中,机器人首先的方向是随机选择的,当它从起点开始出发时,选择了各种各样的方法,完成路径。
但是在机器人碰到红色方块后,给予惩罚,则经过多次后,机器人会避开惩罚位置。
当机器人碰到蓝色方块时,给予奖赏,经过多次后,机器人倾向于跑向蓝色方块的位置。
2.2具体公式
完成奖赏和惩罚的过程表达,就是用值表示吧。首先建立的表是空表的,就是说,如下这样的表是空的,所有值都为0:

在每次行动后,根据奖惩情况,更新该表,完成学习过程。在实现过程中,将奖惩情况也编制成一张表。表格式如上图类似。
而奖惩更新公式为:
贝尔曼方程:
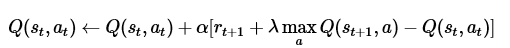
其中的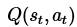 表示当前的Q表,就是上图25行4列的表单。
表示当前的Q表,就是上图25行4列的表单。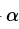 表示学习率,
表示学习率,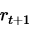 表示下一次行为会得到的奖惩情况,
表示下一次行为会得到的奖惩情况, 表示一个贪婪系数,在这里的公式中,就是说,如果它的数值比较大,则更倾向于对远方的未来奖赏。
表示一个贪婪系数,在这里的公式中,就是说,如果它的数值比较大,则更倾向于对远方的未来奖赏。
该式子在很多网页文本中并没有固定的格式,如贪婪系数,在有些时候是随着步数的增加而递减的(可能)。
3.代码实现
导入对应的库函数,并建立问题模型:
import numpy as np import pandas as pd import time N_STATES = 25 # the length of the 2 dimensional world ACTIONS = ['left', 'right','up','down'] # available actions EPSILON = 0.3 # greedy police ALPHA = 0.8 # learning rate GAMMA = 0.9 # discount factor MAX_EPISODES = 100 # maximum episodes FRESH_TIME = 0.00001 # fresh time for one move
创建Q表的函数:
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))), # q_table initial values
columns=actions, # actions's name
)
return table
行为选择的函数:行为选择过程中,使用这样长的表示也就是为了表达:在边界时候,机器人的路径有些不能选的,要不就超出索引的表格了。
def choose_action(state, q_table):
state_actions = q_table.iloc[state, :]
if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have no value
if state==0:
action_name=np.random.choice(['right','down'])
elif state>0 and state<4:
action_name=np.random.choice(['right','down','left'])
elif state==4:
action_name=np.random.choice(['left','down'])
elif state==5 or state==15 or state==10 :
action_name=np.random.choice(['right','up','down'])
elif state==9 or state==14 or state==19 :
action_name=np.random.choice(['left','up','down'])
elif state==20:
action_name=np.random.choice(['right','up'])
elif state>20 and state<24:
action_name=np.random.choice(['right','up','left'])
elif state==24:
action_name=np.random.choice(['left','up'])
else:
action_name=np.random.choice(ACTIONS)
else: # act greedy
action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
return action_name
当贪婪系数更小时,更倾向于使用随机方案,或者当表初始时所有数据都为0,则使用随机方案进行行为选择。
当np.random.uniform()< =EPSILON时,则使用已经选择过的最优方案完成Qlearning的行为选择,也就是说,机器人并不会对远方的未知目标表示贪婪。(这里的表达是和上述公式的贪婪系数大小的作用是相反过来的)
奖赏表达:函数中参数S,表示state(状态),a表示action(行为),行为0到3分别表示左右上下。该表中,给出了在当前状态下,下一个方向会导致的奖惩情况。
def get_init_feedback_table(S,a):
tab=np.ones((25,4))
tab[8][1]=-10;tab[4][3]=-10;tab[14][2]=-10
tab[11][1]=-10;tab[13][0]=-10;tab[7][3]=-10;tab[17][2]=-10
tab[16][0]=-10;tab[20][2]=-10;tab[10][3]=-10;
tab[18][0]=-10;tab[16][1]=-10;tab[22][2]=-10;tab[12][3]=-10
tab[23][1]=50;tab[19][3]=50
return tab[S,a]
获取奖惩:该函数调用了上一个奖惩表示的函数,获得奖惩信息,其中的参数S,A,同上。当状态S,A符合了下一步获得最终的结果时,则结束(终止),表示完成了目标任务。否则更新位置S。
def get_env_feedback(S, A):
action={'left':0,'right':1,'up':2,'down':3};
R=get_init_feedback_table(S,action[A])
if (S==19 and action[A]==3) or (S==23 and action[A]==1):
S = 'terminal'
return S,R
if action[A]==0:
S-=1
elif action[A]==1:
S+=1
elif action[A]==2:
S-=5
else:
S+=5
return S, R
开始训练:首先初始化Q表,然后设定初始路径就是在0位置(也就是说每次机器人,从位置0开始出发)。训练迭代次数MAX_EPISODES已经在之前设置。在每一代的训练过程中,选择行为(随机或者使用Q表原有),然后根据选择的行为和当前的位置,获得奖惩情况:S_, R。当没有即将发生的行为不会到达最终目的地时候使用。
q_target = R + GAMMA * q_table.iloc[S_, :].max() q_table.loc[S, A] += ALPHA * (q_target - q_table.loc[S, A])
这两行完成q表的更新。(对照贝尔曼方程),当完成时候,即终止,开始下一代的训练。
def rl():
# main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS)
for episode in range(MAX_EPISODES):
S = 0
is_terminated = False
while not is_terminated:
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A) # take action & get next state and reward
if S_ != 'terminal':
q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
else:
print(1)
q_target = R # next state is terminal
is_terminated = True # terminate this episode
q_table.loc[S, A] += ALPHA * (q_target - q_table.loc[S, A]) # update
S = S_ # move to next state
return q_table
if __name__ == "__main__":
q_table = rl()
print('\r\nQ-table:\n')
print(q_table)
注意:
贪婪系数会影响训练时间等。完整代码如下:
import numpy as np
import pandas as pd
import time
N_STATES = 25 # the length of the 2 dimensional world
ACTIONS = ['left', 'right','up','down'] # available actions
EPSILON = 0.3 # greedy police
ALPHA = 0.8 # learning rate
GAMMA = 0.9 # discount factor
MAX_EPISODES = 100 # maximum episodes
FRESH_TIME = 0.00001 # fresh time for one move
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))), # q_table initial values
columns=actions, # actions's name
)
return table
def choose_action(state, q_table):
state_actions = q_table.iloc[state, :]
if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have no value
if state==0:
action_name=np.random.choice(['right','down'])
elif state>0 and state<4:
action_name=np.random.choice(['right','down','left'])
elif state==4:
action_name=np.random.choice(['left','down'])
elif state==5 or state==15 or state==10 :
action_name=np.random.choice(['right','up','down'])
elif state==9 or state==14 or state==19 :
action_name=np.random.choice(['left','up','down'])
elif state==20:
action_name=np.random.choice(['right','up'])
elif state>20 and state<24:
action_name=np.random.choice(['right','up','left'])
elif state==24:
action_name=np.random.choice(['left','up'])
else:
action_name=np.random.choice(ACTIONS)
else: # act greedy
action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
return action_name
def get_init_feedback_table(S,a):
tab=np.ones((25,4))
tab[8][1]=-10;tab[4][3]=-10;tab[14][2]=-10
tab[11][1]=-10;tab[13][0]=-10;tab[7][3]=-10;tab[17][2]=-10
tab[16][0]=-10;tab[20][2]=-10;tab[10][3]=-10;
tab[18][0]=-10;tab[16][1]=-10;tab[22][2]=-10;tab[12][3]=-10
tab[23][1]=50;tab[19][3]=50
return tab[S,a]
def get_env_feedback(S, A):
action={'left':0,'right':1,'up':2,'down':3};
R=get_init_feedback_table(S,action[A])
if (S==19 and action[A]==3) or (S==23 and action[A]==1):
S = 'terminal'
return S,R
if action[A]==0:
S-=1
elif action[A]==1:
S+=1
elif action[A]==2:
S-=5
else:
S+=5
return S, R
def rl():
# main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS)
for episode in range(MAX_EPISODES):
S = 0
is_terminated = False
while not is_terminated:
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A) # take action & get next state and reward
if S_ != 'terminal':
q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
else:
print(1)
q_target = R # next state is terminal
is_terminated = True # terminate this episode
q_table.loc[S, A] += ALPHA * (q_target - q_table.loc[S, A]) # update
S = S_ # move to next state
return q_table
if __name__ == "__main__":
q_table = rl()
print('\r\nQ-table:\n')
print(q_table)